
Future Business Guide KI Empowerment
Unternehmen erfahren zunehmend Druck, sich mit Künstlicher Intelligenz (KI) auseinanderzusetzen, besonders nach dem bedeutenden Wachstum im Jahr 2023..

Trend KI Empowerment: Künstliche Intelligenz als Teil der Vision
In der heutigen, sich schnell wandelnden Digitalära wird ein entscheidender Trend immer deutlicher, der einen tiefgreifenden Einfluss auf die Art und..

Megatrend Research: Die Methode der Trend- und Zukunftsforschung
Angesichts der Komplexität unserer Zeit benötigen Organisationen und Individuen eine belastbare Trend- und Zukunftsforschung, die praktisch anwendbar..

Die neue Zukunftsforschung: Erkenntnisse und Methoden für das 21. Jahrhundert
Die Zukunftsforschung im Umbruch Die Zukunftsforschung, einst geprägt von linearen Prognosen und spekulativen Annahmen, befindet sich mitten in einer..

Megatrendstudie New Work: 13 Trends für die Zukunft der Arbeit
Die Studie „13 Trends für die Zukunft der Arbeit“ entfaltet eine visionäre Karte der Kräfte, die die Landschaft von New Work neu gestalten. Durch..
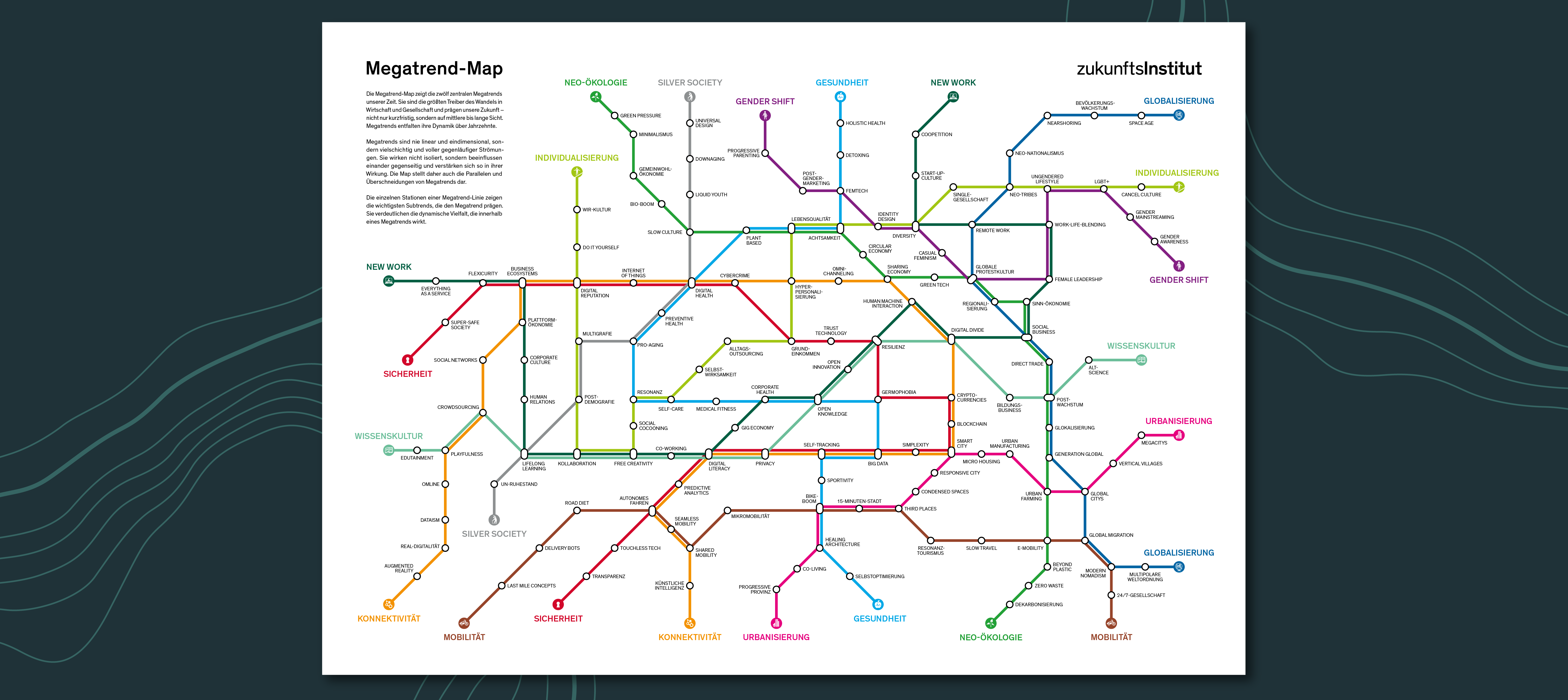
Die Megatrend-Map
Die Megatrend-Map zeigt die 12 zentralen Megatrends unserer Zeit. Sie sind die größten Treiber des Wandels in Wirtschaft und Gesellschaftund prägen..

Trendradar Megatrend New Work: Die Zukunft der Arbeit auf einen Blick
Das Trendradar aus der Megatrendstudie 13 Trends für die Zukunft der Arbeit stellt ein Ergebnis des datenbasierten Megatrend-Research des..

Trend Technosoziale Arbeitswelt: Die Integration von Technologie und Menschlichkeit
Die Technosoziale Arbeitswelt, oft als Arbeit 4.0 bezeichnet, repräsentiert eine fundamentale Veränderung, wie wir Arbeit verstehen und organisieren...

Mental Health @ Work
Was ist Mental Health? Mentale Gesundheit bezieht sich auf den Zustand des emotionalen, psychologischen und sozialen Wohlbefindens einer Person. Es..

Trend Generational Leadership: Alle Altersgruppen zusammen führen
Europas Demografie verändert sich rapide. Zwar wird schon seit Jahrzehnten über die demografische Pyramide diskutiert, nun aber werden die..

Trend Explorer Networks: Innovationsfähigkeit fördern durch Ökosysteme
Die Innovationsfähigkeit von Unternehmen hängt künftig davon ab, ob und wie sie in Innovationsnetzwerken und -ökosystemen agieren. Unsere..

Future Management: Die neue Rolle in Organisationen
Was ist Future Management? – Eine Definition Future Management umfasst alle Maßnahmen und Handlungen, um die Zukunftsfähigkeit von Organisationen zu..

Von Adaptive Erlebniswelten bis Urban Quality of Life: Die wegweisenden Handelstrends im Überblick
Der Handelssektor steht vor Transformationen, die sowohl durch technologischen Fortschritt als auch durch ein wachsendes Bewusstsein für..

Trendradar Retail: Die wichtigsten Entwicklungen für die Zukunft des Handels
Das Trendradar aus dem aktuellen Retail Report stellt ein Ergebnis des datenbasierten Trend Research Retail des Zukunftsinstituts dar. Die darin..

Trend Human Companionship: Die Evolution von HR
In zukünftigen technosozialen Arbeitswelten, in denen Technologie und Sozialität nahtlos interagieren, ist es für Unternehmen essenziell, den..

Discover: New Work Trends mit Pionierpotenzial
Als Abbildung unserer Research-Ergebnisse zum Megatrend New Work sind auf dem Trendradar New Work wertvolle Erkenntnisse für Unternehmen abzulesen...
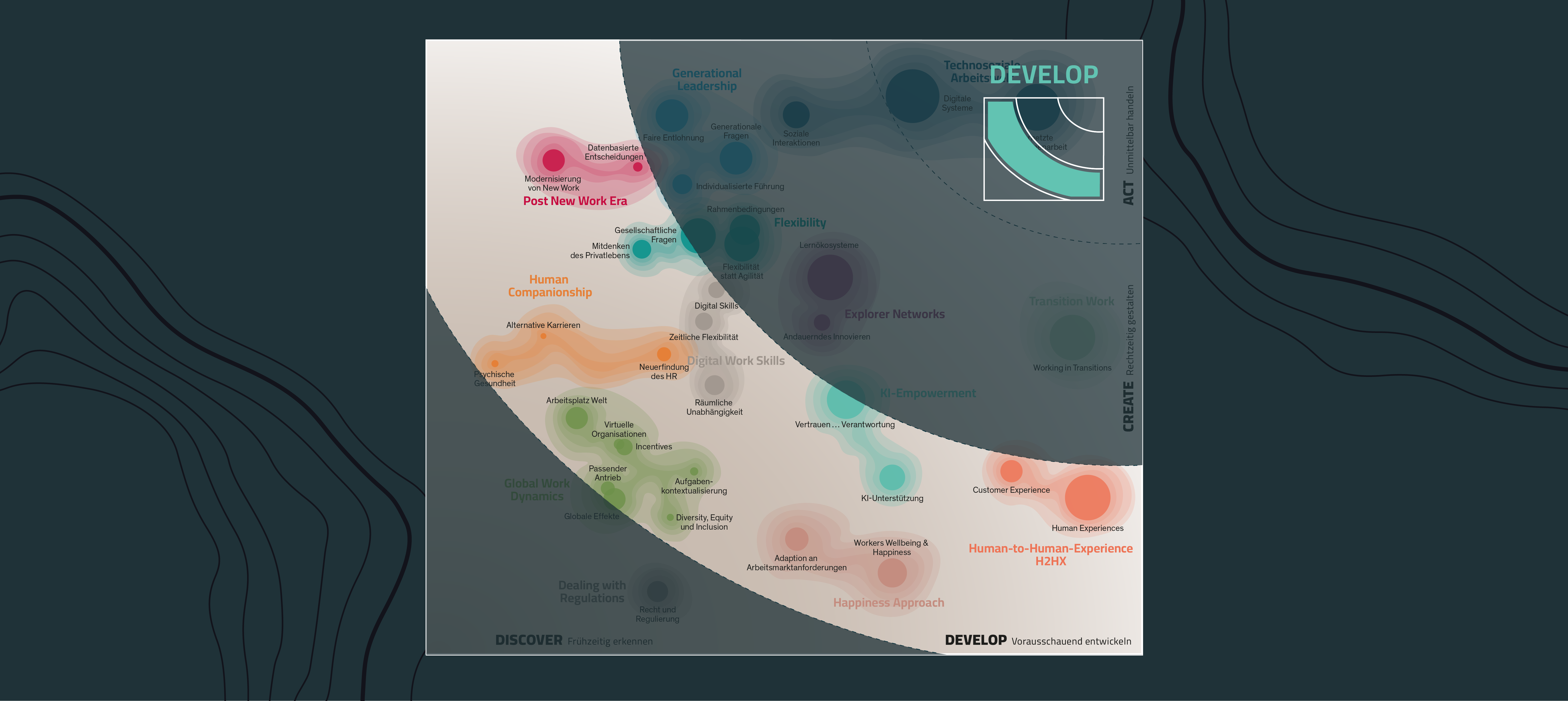
Develop: Für welche New-Work-Trends Sie vorausschauend Strategien entwickeln sollten
Als Abbildung unserer Research-Ergebnisse zum Megatrend New Work sind auf dem Trendradar New Work wertvolle Erkenntnisse für Unternehmen abzulesen...
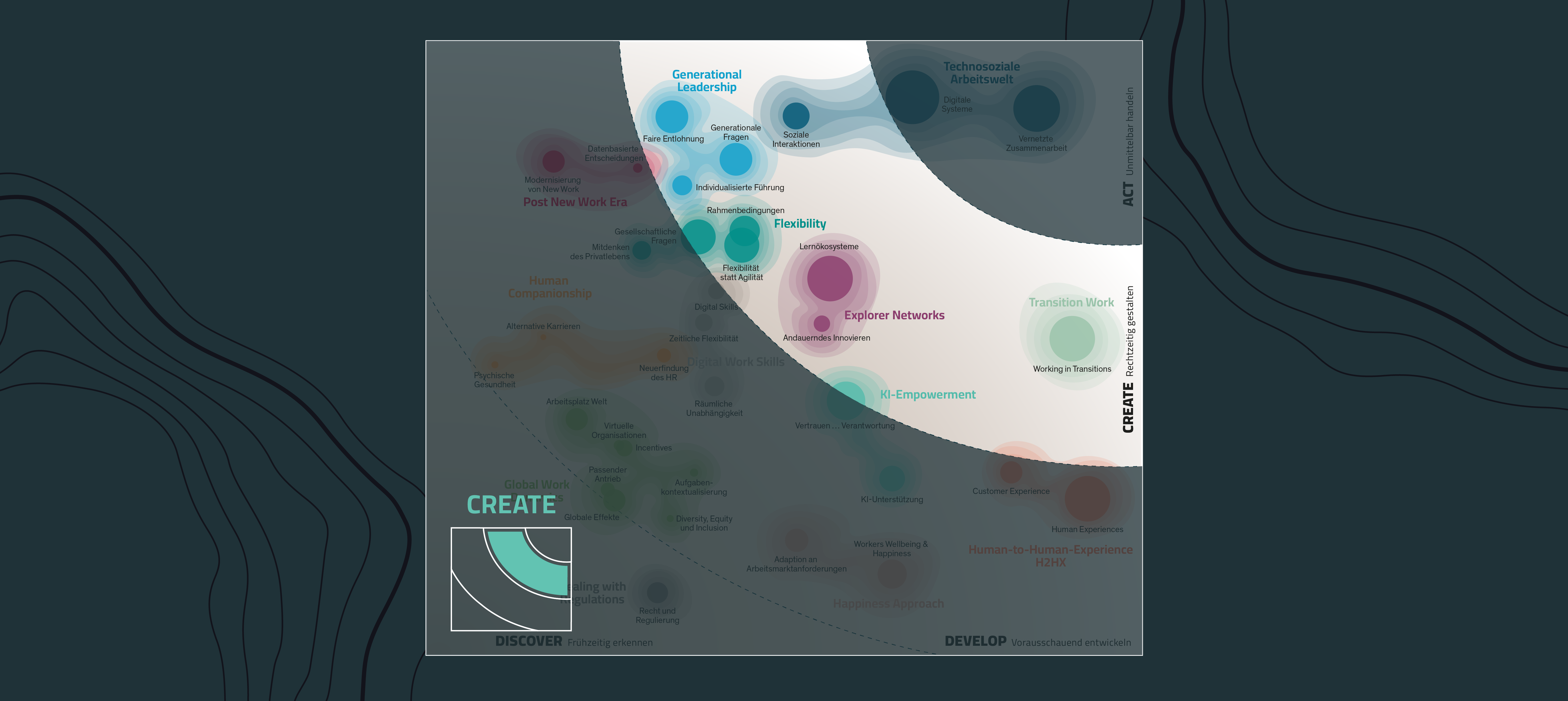
Create: Für welche New-Work-Trends Sie rechtzeitig Maßnahmen gestalten sollten
Als Abbildung unserer Research-Ergebnisse zum Megatrend New Work sind auf dem Trendradar New Work wertvolle Erkenntnisse für Unternehmen abzulesen...

HR und Leadership in der technosozialen Arbeitswelt
Jörg Staff ist Vorstand der deutschen Gesellschaft für Personalführung (DGFP), Aufsichtsrat, renommierter Autor und Speaker, Investor und Executive..
Zukunft der Apotheke: Chancen, Trends und Transformationspotenziale
Herausforderungen und Chancen für Apotheken Klassische Apotheken stehen massiv unter Druck: Die Konkurrenz durch Online-Apotheken stellt ebenso eine..

Gesundheitsmärkte mit großem Zukunftspotenzial
In der sich ständig wandelnden Gesellschaft spielt die Gesundheit eine immer wichtigere Rolle. Diese Entwicklung bietet für innovative Unternehmen,..

Megatrends meets SDG: Treiber für das Erreichen der Nachhaltigkeitsziele
Ein freies und friedliches Leben in Wohlstand auf einem gesunden Planeten für alle Menschen: Um diese Vision einer resilienten Weltgemeinschaft im..

3 Trends als Treiber für nachhaltigen Konsum
Das fragile Konstrukt unserer Konsumwelt, die lange geprägt war von der unreflektierten, verschwenderischen Nutzung von Ressourcen, hat in seinen..
Die treibenden Kräfte hinter der blauen Transition
Wandel und Neues entstehen durch menschliches Handeln – das durch starke Motive aktiviert wird. Das gilt besonders für jenes Handeln, das den Status..

Lebensmittelverpackung: Innovative Alternativen zu Plastik
Wir leben in der „Plastikzeit“: Nützliche Produkte aus Kunststoff umgeben uns, aber auch immenser Plastikmüll. Die radikale Wende der..

Zukunft der Geschlechterrollen
Der Megatrend Gender Shift schafft neue Märkte – und erschüttert die Gesellschaft. Es ist eine Entwicklung, die keineswegs nur Frauen betrifft,..

Von Gendering über Unisex zu Post Gender
Das traditionelle Geschlechtermodell, das Lebensstile, Spielzeug, Kleidung, Berufe, Bücher und vieles mehr nach Geschlecht trennt, verliert zunehmend..

Sechs Beispiele für zukunftsfähige FemTech-Anwendungen
Sechs Best-Practices aus aller Welt, die zeigen, wie moderne und zukunftsfähige FemTech-Modelle die digitalisierte Gesundheitswelt erobern: 1...

Micro-Influencer: Die Ära der passiven Audience ist vorbei
Virtuelle Begegnungen: Je spezieller, desto intensiver Echte Menschen, die bereits eigene Communitys aufgebaut haben, werden zu Markenbotschaftern:..

Kreativität: Das große Missverständnis
Peak Creativity: Kreativität als Massenware Schon lange gilt Kreativität als ein zentraler Treiber des modernen Wirtschaftssystems. Der Bestand von..

Sober Curiosity – den Verzicht genießen
Der Verzicht auf Alkohol wird zum hippen Statement. Doch was genau steckt dahinter? Immer mehr Menschen machen die Erfahrung, dass Alkohol sich zwar..

Was macht Menschen neugierig?
Die neuen Herausforderungen der sich verändernden Wirtschaft erfordern Unternehmen und damit Mitarbeiter, die neugierig sind. Die zu finden darf kein..

Der Lebensstil Moderner Nomade verkörpert das urbane Mindset
Niemand steht so sehr für das urbane Mindset wie der „Moderne Nomade“. Er genießt diese Ungezwungenheit, gestaltet die Dynamik großer Städte aber..

Das leise Comeback des Landes
Unablässig erhöht sich die Leuchtkraft der Städte. Unwiderruflich wachsen die „Schwarmstädte“, in denen Kreativität und Komplexität ein..

Die Zukunft des Landes
Das Interessengebiet der Zukunftsforschung ist gemeinhin die Stadt. Hier findet Innovation statt, hier entsteht Neues, hier treffen Menschen..

Was bedeutet gesunde Ernährung für die Generationen Y und Z?
Gesundheit ist heute das Synonym für ein gutes Leben. Als wichtiges Lebensziel hat sich dieser mächtige, stabile Megatrend tief in unser Bewusstsein,..
Resilienz: Zukunftskraft für Mensch, Gesellschaft, Wirtschaft und Planet
Der Modus der Krise ist zum festen Bestandteil einer neuen Normalität geworden. Die Netzwerkgesellschaft bietet keine langfristig stabilen oder..

Soziale Kipppunkte im Kampf gegen den Klimawandel
Wer sich intensiv mit den Auswirkungen der globalen Erhitzung auseinandersetzt, kann allzu leicht verzweifeln. Uns rennt die Zeit davon. Und im..

Es gibt kein Zurück zur Natur
Herr Dr. van Mensvoort, in Ihrer Forschung beschäftigen Sie sich intensiv mit dem menschlichen Verständnis von Natur. Was ist Ihre Definition von..

Der Mensch ist das großartigere System.
Frau Prof. Dr. Spiekermann, wie intelligent ist KI eigentlich? Sarah Spiekermann: Ob man nun von „Künstlicher Intelligenz“ spricht oder nicht: Jede..
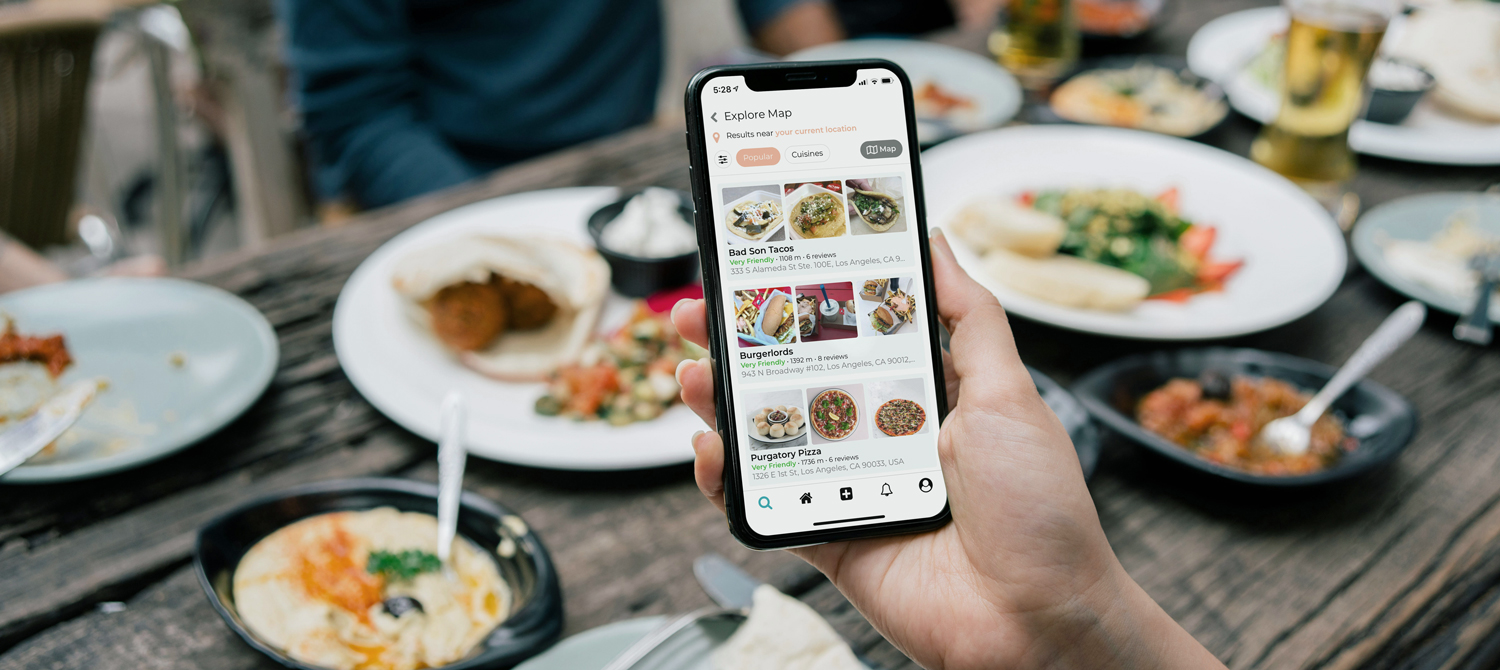
E-Food leitet Strukturwandel in allen Food-Branchen ein
Im Zuge der Pandemie hat E-Food auch im deutschsprachigen Raum an Fahrt aufgenommen. Am offensichtlichsten zunächst mit Blick auf den..

Silverpreneure: Vom Beruf zur Berufung
Raus aus dem Beruf, rein in die Rente, endlich die Füße hochlegen? Dieses Klischeebild einer passiven Seniorenexistenz ist für Silverpreneure, zu..

Alter ist eine Illusion
Alter ist eine Vorstellung von sich selbst, die sich verselbständigt. Wir schaffen uns eine Identität, die sich an individuellen Eckpunkten..

Keine Angst vor Tools!
Es gibt viele Kompetenzen, die wir im 21. Jahrhundert neu entdecken und erlernen müssen. Paradoxie-Kompetenz zum Beispiel: der Umgang mit extrem..

Die Zukunft des Fahrrads
Das Fahrrad reüssiert als urbanes Verkehrsmittel Die Corona-Krise hat die immensen Potenziale des Radfahrens aufgezeigt, denn während der ÖPNV in..

Drohnen-Boom: Die Stunde der Überflieger
Fast täglich laufen Nachrichten über neue Einsatzgebiete von Drohnen über die Bildschirme und spalten die Gesellschaft in vehemente Skeptiker oder..
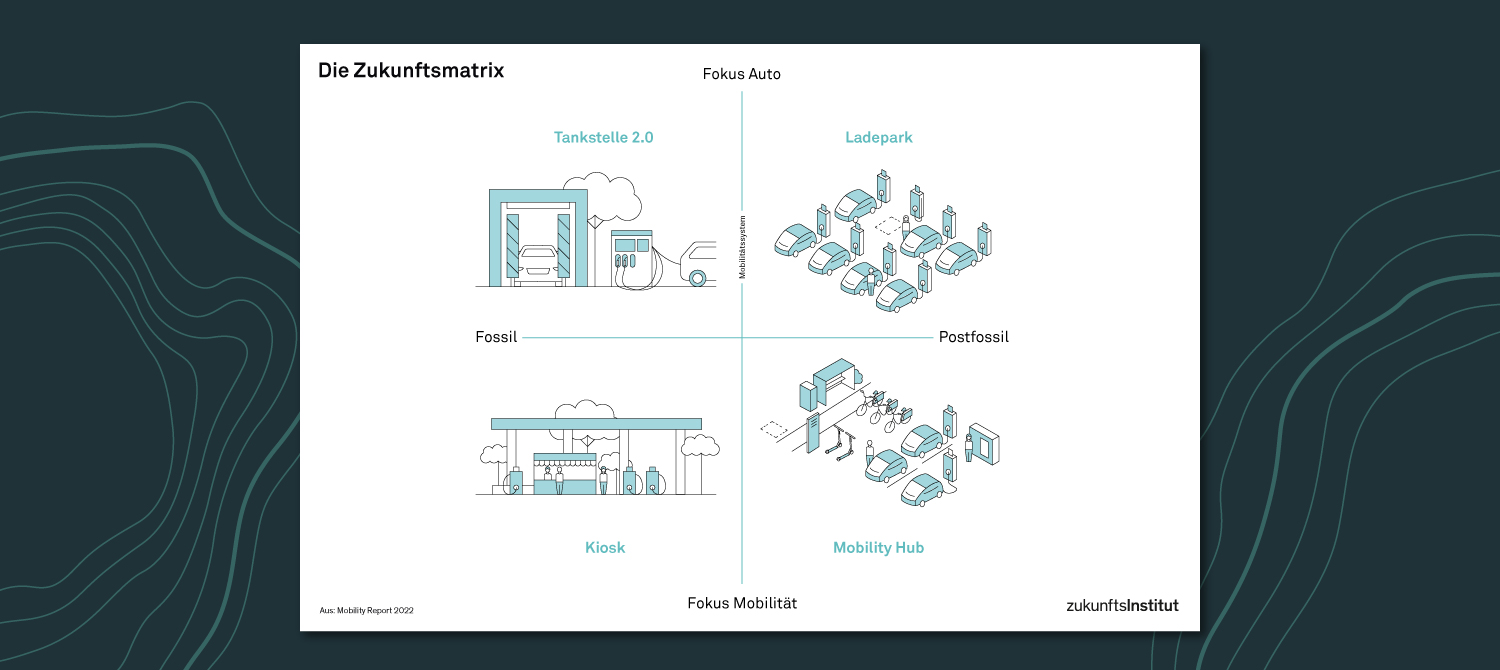
Die Tankstelle der Zukunft: 4 Szenarien
Ändern sich die Anforderungen an die energetischen Bedingungen und an die Mobilität der Zukunft, müssen sich auch die Tankstellen verändern, um..
Das Krankenhaus der Zukunft: 4 Szenarien
Das Jahr 2020 hat die Probleme der Gesundheitssysteme rund um den Globus wie mit einem Brennglas hervorgehoben. Im Fokus der Aufmerksamkeit: Die..

Die 7 Megatrends, die unser Essen besonders stark prägen
Essen ist ein Totalphänomen, das bis zur Unkenntlichkeit mit der Gesellschaft verwoben ist. Das bedeutet, dass sich alle Aspekte des..

Mobility Hubs: Kernelemente der urbanen Verkehrsplanung
Was ist ein Mobility Hub? Was über digitale Plattformen bereits funktioniert, wird auf den physischen Raum übertragen: Mobility Hubs bündeln..

Das Dorf der Zukunft: 6 mögliche Typen
Bis ins 20. Jahrhundert hinein war das Landleben keine Lifestyle-Entscheidung, sondern eine Wirtschaftsform. Auf dem Dorf waren Wohnen und Arbeiten –..

Neo-Tribes
Der Begriff des Neo-Tribalismus geht auf den französischen Soziologen Michel Maffesoli zurück, der in seinem Buch „Le Temps des Tribus“ aus dem Jahr..

Was ist Zukunft? – 11 wertvolle Erkenntnisse
Zukunft ist das, was es noch nicht gibt. Daher ist Zukunft nie real, sondern eine Imagination in unserem Kopf. Ein Gedankenkonstrukt, das wir heute,..

Nachhaltige Mobilität gestalten: 3 strategische Handlungsfelder für Unternehmen
Der Green Deal der Europäischen Kommission hat die Notwendigkeit zum nachhaltigen Wirtschaften in entsprechende Gesetzestexte gegossen. Innerhalb der..

Zukunft der Luftfahrt: 4 Szenarien, wie wir 2040 fliegen werden
Die Luftfahrtbranche erlebt einen Sky Blues: Auf der Kurzstrecke werden durch Klimawandel und Flugscham immer häufiger Bahn oder Reisebus genutzt...

Mobilitätsbudget – Benefit für Unternehmen und Arbeitnehmende
Was ist das Mobilitätsbudget und wie funktioniert es? Das Mobilitätsbudget ist eine zeitgenössische und nachhaltige Alternative zum Pendeln mit dem..

Die Evolution der Medien
Medien begleiten die Menschheitsgeschichte von Anbeginn an. Seit unsere Vorfahren vor hunderttausend Jahren mit Faustkeilen die ersten Symbole in..

Trend: Erschöpftes Europa
Wir befinden uns in einer neuen, globalen Wirklichkeit. Die lang gehegte Idee einer europäischen Vorreiterrolle bröckelt in vielen Bereichen. Nicht..

5 Globalisierungs-Trends, die Unternehmen kennen müssen
Trends sind keine statischen Phänomene, sie befinden sich in einer permanenten Evolutionsschleife. Die Ergebnisse der turnusgemäßen Überprüfung des..

Grenzen überschreiten – individuell, organisational, gesellschaftlich
Ob wir es bemerken oder nicht: Tag für Tag ziehen wir Striche. Wir unterscheiden und markieren, differenzieren, ordnen ein, filtern Relevantes von..

Trend: Rising China –Aufstieg und Ambivalenz Chinas erfordern neue Strategien von Europa
China ist komplex und damit ist auch die Art und Weise, wie Politik und Unternehmen mit der Volksrepublik umgehen sollen, komplex. Auf der einen..

Trend: vom Nearshoring zum Friendshoring
War in den vergangenen Jahren vor allem die Entwicklung vom Off- zum Nearshoring zu beobachten, so ist aus den Forschungsergebnissen unserer..

Trend: Eco Proposition – 3 entscheidende Werte für zukunftsfähige Angebote
Ein Blick in die USA zeigt: Das Umweltbewusstsein ist in allen Altersgruppen der US-Bevölkerung innerhalb der vergangenen Jahre gestiegen – also auch..

Navigieren Sie erfolgreich durch die neue Arbeitswelt
Digitalisierung, Globalisierung und der zunehmende Wunsch nach Flexibilität und Selbstbestimmung verändern die Art, wie wir arbeiten. Um in dieser..

Emotionale Intelligenz am Arbeitsplatz: Ein Leitfaden für Führungskräfte
Emotionale Intelligenz ist eines der zentralen Handlungsfelder im Kontext des Megatrends New Work. Führungskräfte, die in diesem Bereich ihre..

Kollaboration als Schlüssel zum Unternehmenserfolg
Kollaboration als unternehmerische Tugend Der Megatrend Konnektivität verändert die Art und Weise, wie wir arbeiten, grundlegend. Digitale Tools..

Wie durch Mitarbeiterbindung eine erfolgreiche Employee Journey entsteht
In jeder Phase der Employee Journey – von der Einstellung, über die Einarbeitung, die Beförderung ja sogar bis hin zum Austritt aus dem Unternehmen..
Die Bedeutung der digitalen Transformation für Unternehmen und Mitarbeitende
Die digitale Transformation ist ein zentrales Thema für Führungskräfte, HR-Manager und Business Developer, die den Megatrend New Work in ihrem..

Agiles Arbeiten: Die Vorteile für Unternehmen und Mitarbeitende
Agile Work oder agiles Arbeiten ist einer der wesentlichen Bereiche des Megatrends New Work und damit zentral für Führungskräfte, HR, Business..

Wie die Personalabteilung eine zukunftsfähige Employee Experience mitgestalten kann
Die Employee Experience wird im Zeitalter des Megatrends New Work zu einem der wichtigsten Faktoren für den Erfolg von Unternehmen. Sie beschreibt..

Die Zielgruppe ist tot, es lebe der Lebensstil
Sie sind im selben Jahr in England geboren, sind geschieden, haben wieder geheiratet. Ihre Kinder sind erwachsen und ihr Vermögen ist beträchtlich...

Glossar Silver Society: Trendbegriffe und Definitionen
D Digital Health Digitale Technologien spielen bei der Gesundheitsversorgung wie auch beim individuellen Gesundheitsverhalten eine immer größere..

Glossar New Work: Trendbegriffe und Definitionen
B Business Ecosystems Der Begriff des „Business-Ökosystems“ beschreibt die zunehmende Vernetzung von Unternehmen und Branchen – und damit auch das..

OMline: Digital erleuchtet
Die Zeiten, in denen das Internet als Wahrheits-, Demokratie- und Wissensmedium gefeiert wurde, sind längst vorbei. Die unkritische Euphorie der..

Konnektivität: Die Vernetzung der Welt
Internet und Digitalisierung durchdringen alle Bereiche des menschlichen Lebens und verändern Gesellschaft, Ökonomie und Kultur. Das Netz ist längst..

Healthness: Gesundheit wird ganzheitlich
Die selbstreflexive, individualisierte Gesundheit der Selfness-Phase geht in den kommenden Jahren in einen neuen Ansatz über. Über aktive..

Pioniere des Wandels: 3 digitale Lebensstile
Digitalisierung ist längst Teil unseres Alltags und bietet uns tagtäglich eine Fülle von Möglichkeiten und Herausforderungen. Die Vernetzung..

Der neue Stellenwert des Essens: 3 Lebensstile mit einer Vorliebe für Kulinarik
Die lebendige Geschichte und das sinnliche Erleben unseres Essens rücken immer mehr ins Zentrum des Interesses. Der direkte Kontakt mit Händlern und..

Die Potenziale der Globalisierung
Auch wenn die Globalisierung so alt ist wie die Menschheit selbst: Die Machtverschiebungen in Richtung Asien, der Aufbruch Südamerikas, die..

Pioniere zukünftiger Wohnkonzepte
Häufig bestimmen andere – Architekten, Stadtplaner oder Immobilienentwickler – wie wir leben und auch in Zukunft leben werden. Das entspricht aber..

Glossar Sicherheit: Trendbegriffe und Definitionen
A Autonomes Fahren Systeme zum (teil-)autonomen Fahren basieren auf dem Einsatz von Kameras sowie Radar- und Ultraschallsensoren in Fahrzeugen und..

Glossar Globalisierung: Trendbegriffe und Definitionen
B Bevölkerungswachstum Global betrachtet wird die Bevölkerungszahl weiter deutlich ansteigen. Das hat vor allem massive Auswirkungen auf Städte:..

Oldies but goldies: Die vom Handel vergessenen Kunden
Von Zielgruppen zu Lebensstilen In den vergangenen Jahren wurde im Handel meist nur über bestimmte Zielgruppen gesprochen. Viele Unternehmen wollen..

Die Zukunft der Mode: Revolution zwischen Fast und Slow Fashion
Die Modeindustrie wurde durch die globale Gesundheitspandemie ausgebremst und durch die Maßnahmen infolge des Ukraine-Kriegs weiter in..

Glossar Mobilität: Trendbegriffe und Definitionen
15-Minuten-Stadt In einer Viertelstundenstadt soll der Raum so segmentiert und dezentralisiert werden, dass alle notwendigen Bereiche des..

Glossar Wissenskultur: Trendbegriffe und Definitionen
A Alt-Science Fake News und alternative Fakten sind zum Alltag geworden und für manche Menschen zur Grundlage einer alternativen..

Glossar Urbanisierung: Trendbegriffe und Definitionen
15-Minuten-Stadt In einer Viertelstundenstadt soll der Raum so segmentiert und dezentralisiert werden, dass alle notwendigen Bereiche des..

Glossar Konnektivität: Trendbegriffe und Definitionen
A Augmented Reality Die Technologie der Augmented Reality (AR) beschreibt eine computergestützte Verknüpfung der realen mit der virtuellen Welt: eine..

Glossar Gender Shift: Trendbegriffe und Definitionen
C Casual Feminism Feminismus hat sich von einer politischen Bewegung zum Universal- und Alltagsthema gemausert und ist im Mainstream sowie in der..

Glossar Neo-Ökologie: Trendbegriffe und Definitionen
A Achtsamkeit Achtsamkeit ist der wichtigste Gegentrend zur Erregungskultur und permanenten Reizüberflutung des digitalen Zeitalters. Immer häufiger..

Glossar Individualisierung: Trendbegriffe und Definitionen
A Achtsamkeit Achtsamkeit ist der wichtigste Gegentrend zur Erregungskultur und permanenten Reizüberflutung des digitalen Zeitalters. Immer häufiger..

Ich bin kein Roboter!
Am 1. Mai gedenken wir der Solidarisierung der Arbeitnehmer und betonen ihre Forderungen nach einer sinnvolleren und gerechteren Gestaltung der..

Virtual Reality: Die Erschaffung neuer Welten
Virtual Reality (VR) ist zum allgegenwärtigen Thema geworden, das branchenübergreifend enthusiastisch aufgenommen wird und nicht weniger als eine..

Das Comeback des Dorfes
2050 werden nur noch 16 Prozent der Deutschen auf dem Land wohnen, aktuell sind es knapp 25 Prozent. Zudem berechnet das statistische Bundesamt, dass..

Repräsentanten der wichtigsten Megatrends der 2020er Jahre
Die 12 vom Zukunftsinstitut definierten Megatrends wirken sich auf alle Ebenen unseres gesellschaftlichen und wirtschaftlichen Lebens aus. Dennoch..

Silver Society: Die neue Alterskultur
Die Welt wird alt. In Berlin, Tokyo, Moskau, in Buenos Aires, in Pjöngjang. Überall auf der Welt altert die Bevölkerung. Nicht überall gleich..

Authentisch und ästhetisch: Nachhaltigkeit 2.0
Nachhaltigkeit boomt wie nie zuvor, kaum noch eine Werbung oder Produktbeschreibung kommt ohne einen der wohlklingenden Hinweise aus:..

Neo-Ökologie: Die Märkte werden grün
Wollte man den „Beziehungsstatus“ von Ökologie benennen, könnte man nur sagen: Es ist kompliziert. Kein anderer Megatrend löst so heftige Debatten..

Glossar Gesundheit: Trendbegriffe und Definitionen
A Achtsamkeit Achtsamkeit ist der wichtigste Gegentrend zur Erregungskultur und permanenten Reizüberflutung des digitalen Zeitalters. Immer häufiger..

Ambidextrie in Unternehmen fördern
Flexibilität ist in der Ära des Megatrends New Work eines der Kernthemen, mit denen sich Führungskräfte auseinandersetzen müssen. Die Gestaltung..